Diffusion
扩散模型(DDPM)的设计灵感来源于物理学中的扩散现象,其核心逻辑氛围通过向数据中注入噪声来逐渐消除信息的前向过程 Forward Process,以及学习如何从噪声中还原信息的 Backward Process。
Forward Process
在前向过程中,给定一个原始数据点 x0,我们通过一系列微小的步长向其添加高斯噪声,在第 t 步时得到的 xt 服从如下条件概率分布:
q(xt∣x0)=N(xt;αtx0,(1−αt)I)
其中 αt 是预定义的系数,随步数 t 增加而趋向于 0,使得 xt 最终变成纯高斯噪声。
t=1 时(依赖于 t=0)的分布
q1(x1)=∑q(x0)q1(x1∣x0)
考虑 q1(x1∣x0),我们的策略则可以表述为
q1(x1∣x0)=N(x1; 1−β1⋅x0, β1I),β1∈(0,1)
写成重参数化形式就是 x1=1−β1⋅x0+β1ϵ1,这其中,我们通过 β1 向图像添加噪声,并通过 1−β1 减弱/去除 𝑥 中的上下文信息。
数学归纳法得(证明不要求)
xt+1=∏(1−βi)⋅x0+1−∏(1−βi)⋅ϵ
总结一下,就是
- qt+1(xt+1∣x0)=N(xt+1; αt+1⋅x0, (1−αt+1)I)
- xt+1=αt+1⋅x0+1−αt+1ϵ
- 其中 αt+1=∏(1−βi)
如果我们能设计一个比较好的 βt 的策略,使得 t→∞limαt→0。那么 qt(xt∣x0)→N(0,I) 就可以收敛为一个标准的正态分布。
这个是最经典的,还有各种变种,不过目标是一致的。
需要注意的是,�the forward process is fixed,没有可学习参数。
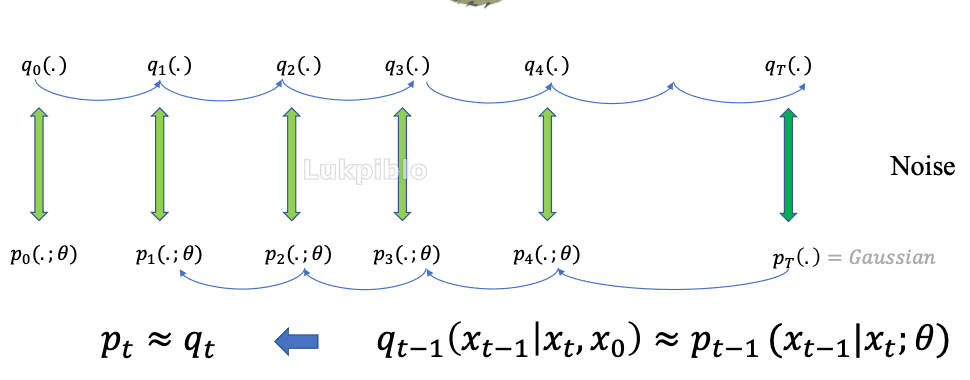
Backward Process
后向过程的目标则是建模一个有意义的、从后往前的条件分布
pt−1(xt−1∣xt; Θ)

DDPM
DDPM 的训练目标是学习一个神经网络 ϵθ(xt,t) 来预测在这一步中所添加的噪声 ϵ 。当模型训练完成后,反向推断过程通过从预测的噪声中估计均值 μθ(xt,t),从而实现从高斯噪声 xT 到数据 x0 的逐步迭代还原。


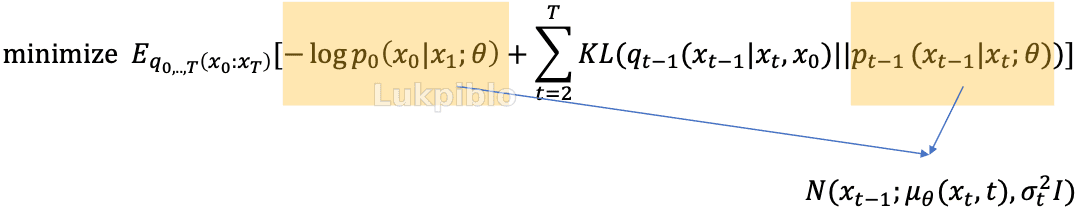

Connection between DDPM and score function
深入到得分匹配(Score Matching)的视角,我们会发现 DDPM 预测噪声的行为本质上是在估计数据分布的“得分函数”。
得分函数(Score Function)在数学上被定义为一个概率密度函数 p(x) 的对数相对于输入变量 x 的梯度,通常写为 ∇xlogp(x)。直观地理解,如果我们将概率密度函数 p(x) 想象成一座山,那么对数操作 logp(x) 只是改变了山的高度比例,而梯度 ∇x 则代表了在这座山上某一点处“最陡峭的上升方向”。因此,得分函数实际上是一个向量场,在空间中的每一个点都指向概率密度增加最快的方向,即指向数据最密集的区域。
在扩散模型中,我们之所以关注它,是因为直接学习复杂的概率分布 p(x) 非常困难,但学习这个“指向数据中心”的梯度场(即得分函数)却相对容易且数值上更稳定。
对于扩散模型中的边缘分布 q(xt),其得分函数指向数据密度增加最快的方向,即引导噪声变回数据的方向。根据贝叶斯公式和高斯分布的性质,预测噪声 ϵθ(xt,t) 与得分函数之间存在如下精确的正比关系:
∇xtlogq(xt)≈−1−αtϵθ(xt,t)
这意味着 DDPM 的训练实际上是在进行一种多尺度的得分匹配 。模型不再试图直接学习复杂的概率密度,而是学习分布的梯度场,这在处理高维图像数据时具有更强的数学稳定性。
Understand DDPM through SDE
如果我们不再将 t 视为离散的步数,而是让时间步长趋于无穷小,扩散模型就可以被描述为一个连续的随机微分方程(SDE)。可以将其理解为描述一个点在噪声干扰下的运动轨迹。前向过程可以被建模为一个由漂移项(引导点向原点靠拢)和扩散项(注入布朗运动噪声)组成的 SDE :
dx=f(x,t)dt+g(t)dw
其中 f(x,t) 决定了确定性的衰减速度,g(t) 控制了噪声注入的强度 。令人惊叹的是,根据随机分析中的 Anderson 逆向定理,每一个这样的前向 SDE 都对应一个等价的反向 SDE 。这个反向方程描述了如何从纯噪声状态逆着轨迹演向数据分布,其公式形式为:
dx=[f(x,t)−g(t)2∇xlogpt(x)]dt+g(t)dwˉ
你会发现,这个逆向演化的核心驱动力正是我们之前提到的得分函数 ∇xlogpt(x) 。
通过 SDE 这一视角,DDPM 与得分匹配模型在数学上得到了完美的统一。DDPM 被视为求解这个反向 SDE 的一种特定离散化形式。这一连续框架不仅加深了我们对扩散机制的理解,还催生了如概率流 ODE(Probability Flow ODE)等技术,允许我们使用常微分方程求解器来加速采样过程,实现了生成质量与采样速度之间的更好平衡 。