TL; DR
PPO首先基于提示和人类偏好数据集训练一个奖励模型,然后使用强化学习找到最大化该奖励模型的策略。
DPO 通过数学推导证明,最优策略 π∗(y∣x) 与参考模型 πref(y∣x) 之间的对数比,与奖励 r(x,y) 存在直接的解析关系。DPO 利用这一关系,直接构造了一个损失函数,允许模型 πθ 在没有显式奖励模型的情况下,通过最大化高质量回答相对于低质量回答的对数概率比(基于 πref),一步到位地优化策略,从而规避了训练奖励模型和使用复杂 RL 算法带来的训练不稳定性。
DPO 在优化人类偏好的同时避免了强化学习。DPO 通过一个简单的分类目标,直接优化最符合偏好的策略,拟合一个隐式奖励模型,该模型的最优策略可以通过封闭形式直接提取。
| 方法 | 训练步骤 | 模型 | 训练方式 | 优点 | 缺点 |
|---|
| RLHF | 先训练奖励模型,再使用 PPO 优化策略 | πθ, πref, rϕ, Vφ | 强化学习和在线采样 | 充分利用人类偏好,上限潜力较高 | 资源消耗大、训练不稳定、超参数敏感 |
| DPO | 直接利用偏好数据训练 Actor 模型 | πθ, πref | 类似 SFT 监督学习 | 流程简化、训练稳定、资源消耗低 | 性能提升上限可能低于 RLHF |
Derive the DPO Objective
这一节主要讲解DPO的推导过程。
Theoretical Analysis of RLHF Objective
在大规模语言模型对齐中,我们希望利用人类反馈强化学习 (RLHF) 来优化模型输出。输入 x 来自数据集 D,模型生成回答 y; 待训练的模型记为 π(y∣x),而参考模型记为 πref(y∣x) (通常为SFT模型),同时引入奖励函数 r(x,y) 衡量回答质量。在 RLHF-3-Modelling-Human-Feedbacks#RLHF Pipeline 中,我们推导了 RLHF 的目标是
πmaxEx∼D,y∼π(y∣x)[r(x,y)]−βDKL[π(y∣x)∥πref(y∣x)]
其中 β 为调节奖励与参考模型偏差的超参数。利用 KL 散度的定义
DKL(π(y∣x)∥πref(y∣x))=Ey∼π(y∣x)(logπref(y∣x)π(y∣x))
式 (1) 可重写为
πmaxEx∼D,y∼π(y∣x)(r(x,y)−βlogπref(y∣x)π(y∣x))
将上式转换为最小化问题并除以 β 即得
πminEx∼D,y∼π(y∣x)(logπref(y∣x)π(y∣x)−β1r(x,y))
假设存在一个最优策略分布 π*(y∣x) 使 (4) 式全局最优,利用拉格朗日乘子法求得最优策略分布满足如下形式。基于变分法,可令
π*(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))
其中配分函数 Z(x) 为了实现最优策略分布的归一化,定义为
Z(x)=y∑πref(y∣x)exp(β1r(x,y))
注意到:
- Z(x) 对所有可能的 y 求和,实现归一化,使得 π*(y∣x) 构成合法的概率分布。
- Z(x) 是 x 的函数,与待优化的 Actor 模型 π 无关。
对 (5) 式取对数得到
logπ*(y∣x)=logπref(y∣x)+β1r(x,y)−logZ(x)
反推奖励函数,发现其与与最优策略的对数比有关
r(x,y)=β(logπref(y∣x)π*(y∣x)+logZ(x))
Direct Preference Optimization
这一节很重要。在 PPO 等 RL 方法中,我们通过预先训练一个奖励模型 rϕ ,通过梯度方法近似下面的解析解找到该奖励模型条件下的最优策略 π*。
logπθ*(y∣x)=logπref(y∣x)+β1rϕ*(x,y)−logZ(x)
DPO 引入了对奖励模型的另一种参数化方法。因为我们最终需要的是这个最优策略,那不妨假设我们能够不依赖奖励模型就找到这样一个最优策略。我们先把要优化的策略参数化,通过找到最优化的策略,导出适合这个最优策略的奖励模型1,即
rθ(x,y)=β(logπref(y∣x)πθ(y∣x)+logZ(x))
DPO Loss
将上式代入 RLHF-3-Modelling-Human-Feedbacks#Bradley–Terry 与奖励模型训练 的损失函数 (⋆) 式 ,在成对比较中,对于相同输入 x,两个回答 yw 和 yl 均包含相同的 logZ(x) 项,因此在计算奖励差值时,该项会被消去。这样,我们就可以把 RLHF 损失函数简化为只与 πθ 有关了。
我们最终得到 DPO 的损失函数
minimizeLDPO(πθ,πref)=−E(x,yw,yl)∼D(logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x)))
该损失函数针对待训练 Actor 模型 πθ 而设,通过比较其在高质量回答 yw 与低质量回答 yl 上、相对于参考模型 πref 的对数概率比来区分好坏回答。
直观地看这个损失函数的合理性:
- 当 πθ 在 yw 上的相对概率比远大于 yl 时,σ 输出更接近 1,损失更小;
- 反之,若 πθ 对 yl 的相对概率权过大,则损失增加。
- 参数 β 用于放大或缩小这些对数比的差值,从而调节模型对好坏答案的区分强度。
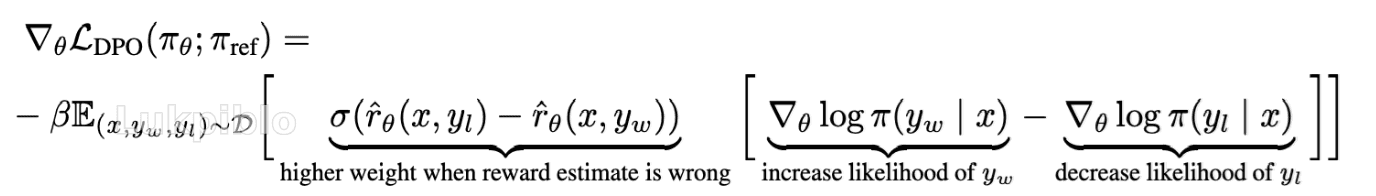
从 ∇LDPO 来看:
- 直观地说,损失函数的梯度增加了偏好的回答的概率,并减少了不偏好的回答的概率
- 权重衡量了隐式奖励模型错误排序的程度,优先学习那些模型做错的的样本,并防止模型在已
经正确的样本上过度优化
- β是缩放程度,偏离程度,衡量KL距离。不用这个参数,导致模型退化
DPO 的理论贡献
Your Language Model Is Secretly a Reward Model.
- 无需拟合一个显式的奖励函数
- 无需执行强化学习 (RL) 来训练策略
- DPO仅用一个最大似然目标来训练策略
- DPO并不限制学习的奖励模型的类别,并且允许准确恢复最优策略。
Instability of Actor-Critic Algorithms.
- DPO能够诊断标准Actor-Critic算法(如PPO)在RLHF中的不稳定性(f不会影响最优策略的最终解析解,但可能导致梯度高方差和不稳定性)
- DPO重参数化方法将优化问题完全转换到了似然域,消除了对价值和基线的需求